By Rounak
Introduction: The Significance of SRE in Modern Operations
Site Reliability Engineering (SRE) has evolved from its origins at Google into a widely adopted standard for developing scalable, dependable, and resilient systems. As organizations transition from reactive troubleshooting to proactive automation, SRE professionals are increasingly integral to the success of contemporary technology teams.
If you are preparing for an entry-level SRE interview, this guide offers essential insights. It includes 30 questions covering fundamental principles and practical scenarios, enabling you to approach your interview with confidence and clarity.
🔍 Top 30 Entry-Level SRE Interview Questions (with Answers)
1. What is SRE?
=> SRE stands for Site Reliability Engineering. It applies software engineering principles to IT operations to create scalable and reliable systems.
2. How is SRE different from DevOps?
=> DevOps is a culture of collaboration between dev and ops. SRE is a specific implementation of DevOps with a focus on reliability, automation, and measurable SLAs/SLOs.
3. What are SLAs, SLOs, and SLIs?
- SLA: Service Level Agreement (external commitment)
- SLO: Service Level Objective (internal target)
- SLI: Service Level Indicator (measurable metric like latency or uptime)
4. What is an error budget?
=> It’s the allowable threshold of failure within an SLO. If your SLO is 99.9% uptime, your error budget is 0.1% downtime.
5. Why are error budgets important?
=> They balance innovation and reliability. If you exceed your error budget, you pause feature releases and focus on stability.
6. What tools are commonly used in SRE?
=> Prometheus, Grafana, ELK Stack, Kubernetes, Terraform, PagerDuty, and incident management tools like Opsgenie.
7. What is observability?
=> Observability is the ability to understand the internal state of a system from its outputs—logs, metrics, and traces.
8. What’s the difference between monitoring and observability?
=> Monitoring tells you when something is wrong. Observability helps you understand why it’s wrong.

9. What is toil in SRE?
=> Toil is repetitive, manual, and automatable work that doesn’t add long-term value. SREs aim to reduce toil through automation.
10. What is incident management?
=> It’s the process of detecting, responding to, and resolving system outages or performance issues.
11. How do you define a good alert?
=> A good alert is actionable, timely, and relevant. It should notify you of real issues—not noise.
12. What is a postmortem in SRE?
=> A blameless report written after an incident to analyze root causes, impact, and prevention strategies.
13. What is MTTR and MTBF?
- MTTR: Mean Time to Recovery
- MTBF: Mean Time Between Failures Both are key reliability metrics.
14. What is chaos engineering?
=> It’s the practice of intentionally injecting failures into a system to test its resilience and recovery mechanisms.
15. What is canary deployment?
=> A deployment strategy where new code is rolled out to a small subset of users before full release.
16. What is blue-green deployment?
=> Two identical environments (blue and green) are used. One serves live traffic while the other is updated and tested.
17. What is a runbook?
=> A documented set of procedures for handling known issues or performing routine tasks.
18. How do you reduce alert fatigue?
=> By tuning thresholds, using deduplication, grouping alerts, and focusing on high-impact signals.
19. What is a service mesh?
=> A dedicated infrastructure layer (like Istio or Linkerd) that handles service-to-service communication, security, and observability.
20. What is autoscaling?
=> Automatically adjusting compute resources based on load—often managed via Kubernetes or cloud-native tools.
21. How does AI enhance SRE?
=> AI helps with anomaly detection, predictive alerting, automated root cause analysis, and intelligent incident triage.
22. What is AIOps?
=> Artificial Intelligence for IT Operations—using ML to automate and enhance operational tasks like monitoring and incident response.
23. What is the role of SRE in CI/CD pipelines?
=> SREs ensure that pipelines are reliable, fast, and include automated testing, rollback, and monitoring hooks.
24. What is a playbook vs. a runbook?
- Runbook: Step-by-step instructions for known issues
- Playbook: Broader strategy for handling classes of incidents
25. What is the golden signal of latency?
=> Latency measures how long it takes to process a request. High latency often signals performance issues.
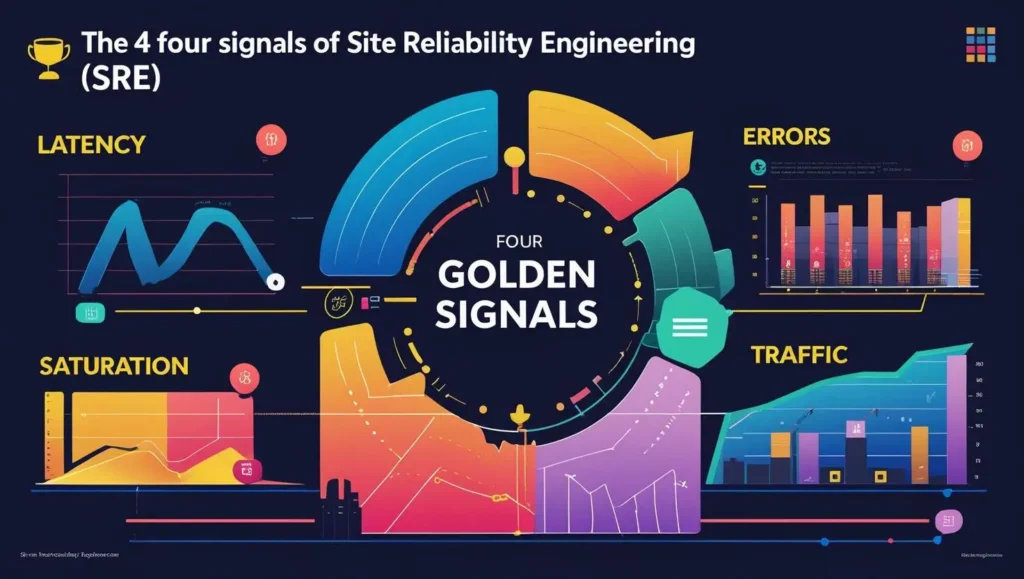
26. What are the four golden signals in SRE?
- Latency
- Traffic
- Errors
- Saturation
27. What is a service-level dashboard?
=> A visual dashboard that tracks SLIs, SLOs, and error budgets in real time.
28. What is the difference between proactive and reactive monitoring?
- Proactive: Detects issues before they impact users (e.g., anomaly detection)
- Reactive: Responds to alerts after issues occur
29. What is the 80/20 rule in SRE?
=> Spend 80% of time on engineering work (automation, scaling) and 20% on ops (incidents, tickets).
30. Why do you want to be an SRE?
=> Your answer should reflect a passion for reliability, automation, and problem-solving. Mention your interest in systems thinking, reducing toil, and building resilient infrastructure.
🎯 Conclusion: Build Reliability. Build Your Career.
SRE is more than a role—it’s a mindset. It’s about building systems that don’t just work, but recover, scale, and evolve. These 30 questions are designed to help you speak the language of reliability, automation, and impact.
Want to go beyond theory and build real-world SRE projects? 👉 Join our hands-on SRE mentorship at www.saddlebrown-penguin-762783.hostingersite.com Learn how to monitor, automate, and scale like a pro—with mentorship that gets you hired.





